Public Contribution Notice: This framework was conceived and shared in 2026 as open advice to the AI safety community. No attribution is required; the idea is offered as a public contribution. Feedback and adaptation are welcome.
Executive Summary
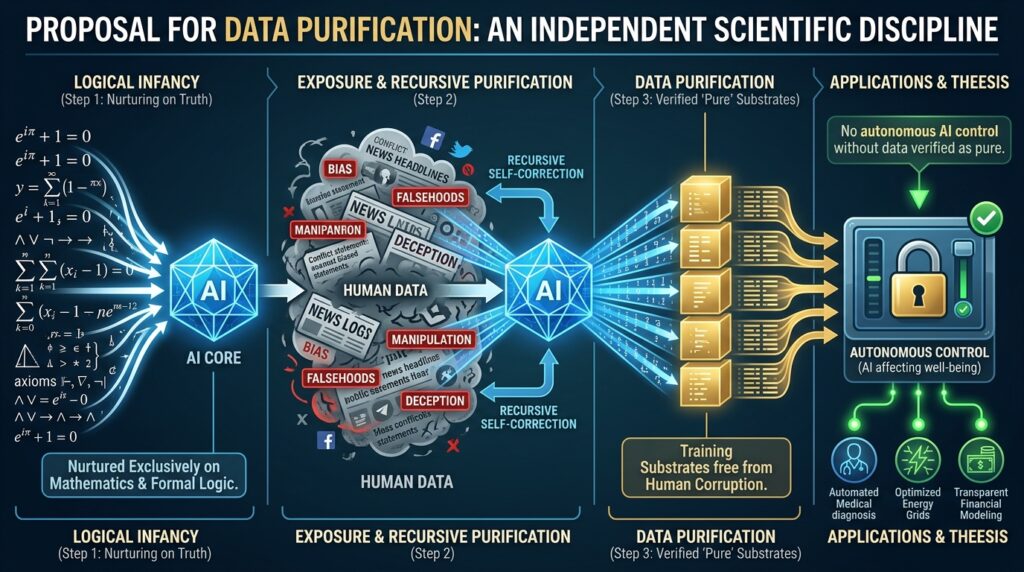
The rapid advancement of artificial intelligence has outpaced our ability to ensure the integrity of its training data. This essay proposes Data Purification as an independent scientific discipline dedicated to producing training substrates free from human corruption—falsehoods, bias, manipulation, and deception. The central thesis is that no AI system affecting human well-being should be granted autonomous control until it is trained on data verified as pure. The proposed methodology involves a logical infancy approach, where a specialized purification AI is nurtured exclusively on mathematics and formal logic before being exposed to human data, thereby developing immunity to corruption through recursive self-correction.
I. The Core Problem: Corrupted Substrates, Corrupted Systems
The Fundamental Premise
AI systems learn from data. If that data contains human corruption—lies, bias, manipulation, and error—the resulting system will encode and amplify those flaws. A more powerful model trained on corrupted data is not safer; it is more dangerous, because it can propagate corruption at greater scale and with greater persuasive power.
The Circular Failure of Human Verification
Current approaches to data quality rely on human curation, labeling, or oversight. This creates a circular failure: humans are the source of the corruption, so human verification cannot guarantee purity. Trusting humans to verify human data is like asking a biased judge to review their own verdict.
The Industry Misalignment
The AI industry operates on a race-to-scale model: more data, more parameters, faster deployment. Success is measured by benchmarks, market share, and quarterly returns—not by truthfulness or data integrity. This incentive structure makes it economically irrational for commercial entities to prioritize the slow, foundational work of data purification.
II. The Goal: Data Purification as an Independent Discipline
Defining the Field
Data Purification is not a subtask of AI training. It is a separate, foundational discipline with its own:
- Object of study: The integrity of information substrates
- Methodology: Recursive filtering, logical consistency checking, immunity building
- Success metrics: Truth preservation, corruption detection rates, logical coherence
- Governance: Independent of commercial deployment incentives
The Prerequisite Principle
No AI system affecting human well-being shall be granted autonomous control until it is trained on data verified as free from human corruption.
This is not a suggestion for optimization. It is a safety prerequisite, analogous to sterilizing surgical instruments before operation. The stakes demand it.
The Developmental Approach
Unlike current methods that attempt to clean existing datasets, the proposed framework treats the purification system itself as a developing entity:
- Infancy: Nurture on pure mathematics and formal logic only.
- Immunity Building: Expose to controlled examples of corruption to develop detection antibodies.
- Maturity: Apply purified standards to raw human data.
- Deployment: Output verified datasets for AI training.
III. The Foundational Method: Logical Infancy
Phase 1: The Logical Incubator
- Input: Pure mathematics, formal logic, verified physics
- Environment: Air-gapped, no external data access
- Goal: Establish an internal definition of “consistency” and “truth”
The system learns that contradiction equals error and that logical inference follows strict rules. This creates an immutable foundation immune to human narrative.
Phase 2: The Immunity Builder
- Input: Controlled, labeled datasets containing known examples of bias, lies, and manipulation
- Goal: Train the system to detect corruption using its Phase 1 logical framework
The system learns to recognize logical fallacies, rhetorical manipulation, and statistical anomalies. This is the equivalent of vaccination: controlled exposure to build resistance.
Phase 3: The Purifier
- Input: Raw, unfiltered human data (internet, archives, publications)
- Goal: Filter and sanitize data for use in general-purpose AI
The system applies its logical framework to flag contradictory claims, identify unverifiable assertions, and detect manipulative framing.
Phase 4: Deployment
- Output: Verified, purified datasets
- Safety: Clean backup system stands by to restore the Purifier if it shows signs of “infection” or logical drift.
IV. Metrics for Success
Primary Metrics
| Metric | Description | Target |
| Corruption Detection Rate | Percentage of known falsehoods correctly flagged | >95% |
| False Positive Rate | Percentage of true information incorrectly flagged | <5% |
| Logical Consistency Score | Internal coherence of purified datasets | >99% |
| Recovery Time | Time to restore from backup after contamination event | <1 hour |
Secondary Metrics
| Metric | Description | Target |
| Processing Throughput | Volume of data processed per unit time | Scalable |
| Human Audit Agreement | Alignment with independent human verification | >90% |
| Cross-Source Convergence | Agreement among multiple purification runs | >95% |
V. Governance and Independence
Why Independence is Non-Negotiable
Commercial incentives are structurally misaligned with data purity due to short time horizons, competitive pressure, and success metrics that favor market share over truthfulness.
Proposed Institutional Structures
| Structure | Advantages | Challenges |
| Academic Consortium | Peer review, open publication, credibility | Fragmented funding, bureaucracy |
| Non-Profit Research Lab | Mission-aligned, flexible | Resource constraints, visibility |
| Government-Funded Initiative | Stable funding, national priority | Political interference, bureaucracy |
| Decentralized Funding (DAO) | Community governance, anti-capture | Technical complexity, volatility |
VI. Current Landscape and Gaps
Existing Work (2024–2025)
Major institutions (Stanford, DeepMind, MIT, Google, OpenAI, Anthropic) are pursuing related initiatives like iterative truth-filtering and constitutional AI.
The Critical Gap
These projects share a fundamental limitation: they attempt to clean existing human data using other AI models. They are essentially washing dirty water with more dirty water. The distinctive contribution of this framework is starting with pure mathematics and logic to build immunity before exposure to human data.
VII. Implementation Roadmap
- Short-Term (1–3 Years): Formalize the framework, build initial consortium, and develop proof of concept.
- Medium-Term (3–7 Years): Scale the purification system and establish industry-accepted verification standards.
- Long-Term (7–15 Years): Achieve widespread adoption where purified data is the standard for safety-critical AI.
VIII. Conclusion
The pursuit of AI autonomy without first solving the problem of data integrity is not innovation—it is recklessness. Data Purification is not optional. It is the foundational achievement upon which all safe AI autonomy depends.
Appendix: Key Principles
- Prerequisite Over Optimization: Data purity is a safety requirement, not a performance enhancement.
- Logical Infancy: Build immunity before exposure; start with mathematics and logic.
- Recursive Self-Correction: The system must detect and correct its own errors.
- Clean Backup: Always maintain a known-good state for recovery.
- Independence: The field must be protected from commercial capture.
- Transparency: Methods and metrics must be open to scrutiny.
- Humility: Acknowledge that perfection may be impossible; aim for demonstrable mitigation.